Extract hardcoded UI strings before they become product debt
Find strings across components, classify them, create content models, and prepare translation-ready output in Git.
{
"title": "Govern content your AI ships",
"cta": "Start free trial",
"badge": "New",
"locale": "en"
}
# typed, validated, queryable
Problem
Hardcoded strings are invisible content debt
AI coding tools make this worse by producing labels, headings, empty states, validation text, and marketing copy directly inside components. The product ships faster, but future edits become scattered source changes.
- UI copy hidden in components
- Localization blocked by source edits
- Content review mixed with unrelated code changes
<h1>Start your free trial</h1>
<p>No credit card required</p>
<button>Get started</button>
<a href="/pricing">See plans</a>
# 124 strings scattered across 47 files
# invisible content debt
Discovery
Scan the source before choosing a model
Contentrain MCP scan can inspect candidate strings and source graph context. That lets the team decide what belongs in dictionaries, collections, documents, or singleton content instead of guessing.
- Candidate extraction with filters
- Source graph context
- Agent-readable scan output
$ contentrain scan ./src
Scanning source for hardcoded strings…
✓ Scanned 47 files
123 candidate strings found
marketing/hero 18
ui/navigation 24
ui/buttons 31
→ extracted to branch cr/normalize/marketing
✓ Ready for review in Git
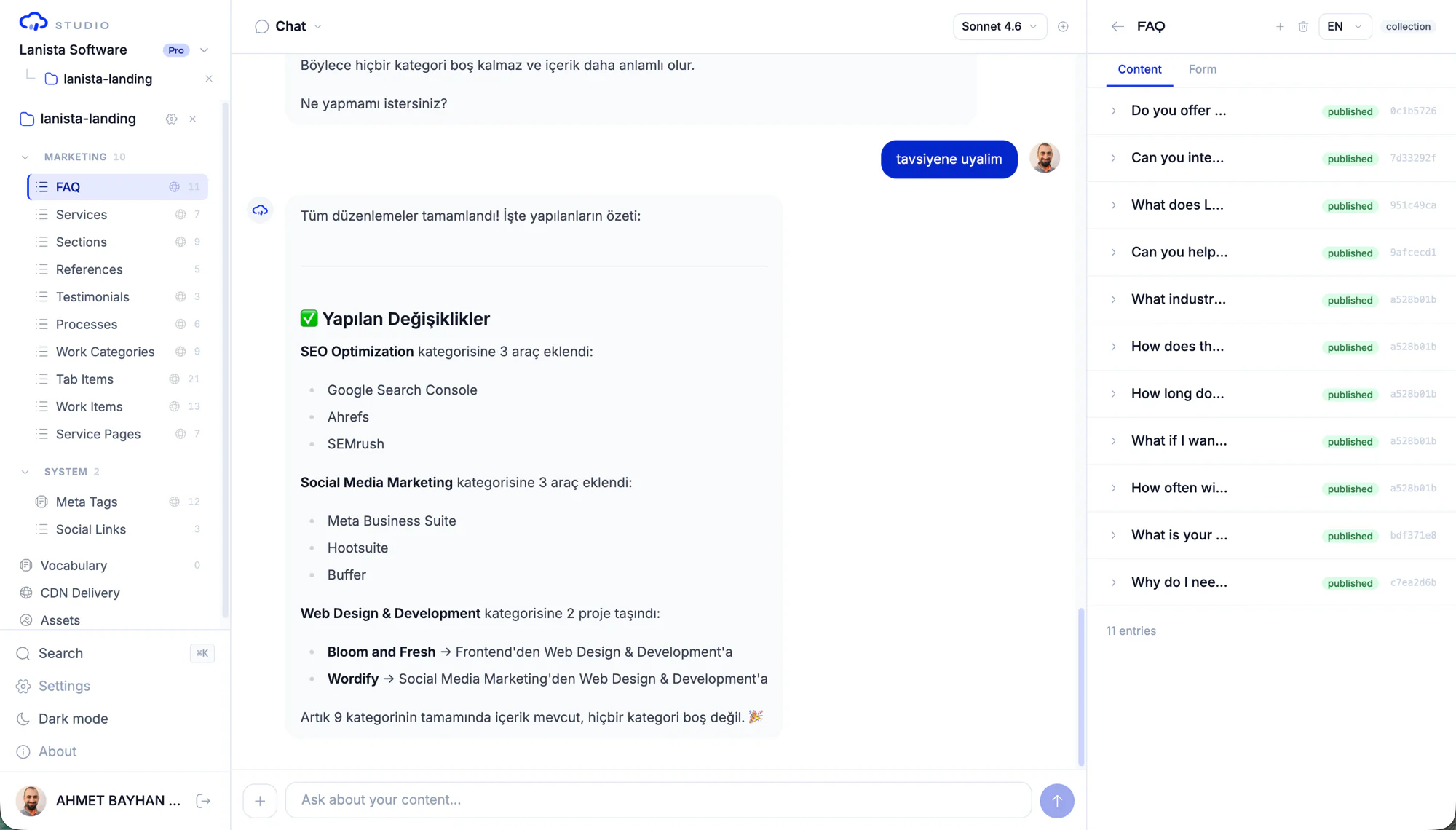
Extraction
Extract strings into governed content entries
Approved strings are written as Contentrain content with source tracking. The source remains unchanged during extraction, which makes the content branch easier to review.
- Content entries created through MCP
- Source file and line traceability
- Model-aware content structure
Reuse
Patch source only after content is ready
Reuse patches replace hardcoded values with generated content access. This makes the code cleaner while keeping the migration reviewable.
- Framework-specific replacement expressions
- Import handling for generated access
- Conflict checks against the original source value
$ contentrain validate
Validating content against schemas…
◇ Validation complete
Models checked: 9
Entries checked: 56
✓ Errors: 0
✓ Warnings: 0
All content valid — safe to merge
Outcome
Unlock localization and team review
Once strings live in content files, locale parity, translation, SEO quality, and content approval can be managed as content workflows instead of source hunts.
- Locale-aware content files
- Validation for required fields and parity
- Studio review when non-developers participate
Common questions
Is this only for localization?
No. Localization is one benefit, but the broader value is making UI text editable, reviewable, reusable, and visible to agents.
Can I extract everything at once?
You can scan broadly, but high-quality adoption usually starts with meaningful product surfaces: navigation, onboarding, empty states, CTAs, and repeated UI labels.
What prevents unsafe source patches?
Normalize separates extraction from reuse, validates inputs, checks conflicts, and keeps changes reviewable before they are applied.
Next paths
Continue through the content system
Start local. Scale to Studio.
Build a governed content layer before content becomes product debt.
Start locally with the MIT packages. Add Studio when teams need review, roles, structured editing, managed delivery, or deployment control.